Best 3D Models With Comfyui
Posted on February 1, 2025 - Comfyui

Hey there! I've been playing around with this cool new tool called ComfyUI 3D Pack, and I want to tell you all about it. It's basically like having a 3D artist in your computer - but one that works really fast and doesn't need coffee breaks!
What's This All About?
You know how making 3D stuff usually means spending hours learning complicated software? Well, this tool changes everything. It's like having a magic wand that turns regular pictures into 3D models. I'm not kidding - you can take a photo of your cat and turn it into a 3D model that you can spin around and look at from any angle!
The best part? It works right inside ComfyUI, which is already super popular for making AI art. If you're already using ComfyUI, you'll feel right at home.
Cool Stuff You Can Do
Let me tell you about some of the awesome things this pack can do. It's like having a whole toolkit of 3D magic tricks:
Single-Stage Models
1. TRELLIS (microsoft/TRELLIS)
- Purpose: Single image to 3D mesh with RGB texture
- Model Location: huggingface.co/JeffreyXiang/TRELLIS-image-large
- Input: Single image
- Output: Textured 3D mesh
TRELLIS introduces a structured 3D latent representation (SLAT) that combines sparse 3D grids with dense multi-view visual features from foundation models, enabling high-quality 3D generation across multiple formats (Radiance Fields, 3D Gaussians, meshes). The method employs Rectified Flow Transformers trained on 500K 3D assets, achieving state-of-the-art results through:
- Unified Representation - SLAT's hybrid structure preserves both geometric detail (via sparse active voxels) and textural richness (through vision model features)
- Scalable Architecture - 2B parameter model supporting text/image-conditioned generation
- Versatile Outputs - Native support for different 3D representations without post-processing
- Editing Capabilities - Enables asset variants and local manipulations through latent space operations
2. StableFast3D (Stability-AI/stable-fast-3d)
- Purpose: Quick single image to 3D mesh conversion
- Special Note: Requires Stability-AI terms agreement
- Location: Under Checkpoints/StableFast3D
- Requirements: Huggingface token in system.conf
Stable Fast 3D is Stability AI's real-time 3D generation model that converts single images into textured 3D meshes in 500ms. Key features:
- Ultra-Fast Conversion - Generates UV-unwrapped meshes with material parameters in 0.5s (7GB VRAM) vs previous 10-minute generation times
- Enhanced Outputs - Produces:
- Illumination-reduced albedo textures
- Optional quad/triangle remeshing (+100-200ms)
- Normal maps and material parameters
- Applications - Targets game development (background assets), AR/VR prototyping, e-commerce 3D modeling, and architectural visualization
- Access - Available through:
- Hugging Face (Community License for ≤$1M revenue)
- Stability AI API
- Stable Assistant chatbot with AR preview
- Technical Base - Built on TripoSR architecture with retrained weights and mesh generation improvements
The model demonstrates a 1200x speed improvement over previous SV3D while maintaining output quality, positioning it as a rapid prototyping tool for 3D content creation.
Two-Stage Models
3. Hunyuan3D_V2 (tencent/Hunyuan3D-2)
Stage 1: Single image → 3D mesh shape Stage 2: Shape + reference image → Textured 3D mesh
- Weights: huggingface.co/tencent/Hunyuan3D-2/tree/main
Hunyuan3D-2 is Tencent's scalable 3D generation system combining a 2.6B parameter shape model (Hunyuan3D-DiT) and 1.3B parameter texture model (Hunyuan3D-Paint). Key technical features:
-
Architecture
- Shape Generation: Flow-based diffusion transformer produces meshes from images/text
- Texture Synthesis: Geometry-aware diffusion model (1024px+ resolution)
- Unified pipeline supports both generated and custom meshes
-
Performance
- Outperforms SOTA in metrics: CMMD (3.193), FID_CLIP (49.165), CLIP-score (0.809)
- Processes shape+texture in 24.5GB VRAM
-
Deployment
- Blender integration via addon
- API server with GLB output
-
Ecosystem
- Community contributions: Windows tools, ComfyUI plugins
- Enterprise platform (Hunyuan3D Studio) for asset management
- Active development with TensorRT optimization roadmap
The system demonstrates state-of-the-art performance in conditional 3D asset generation while maintaining practical usability through multiple integration pathways.
4. Hunyuan3D_V1 (tencent/Hunyuan3D-1)
Stage 1: Single image → multi-views Stage 2: Multi-views → Textured 3D mesh
- Weights: huggingface.co/tencent/Hunyuan3D-1/tree/main
Tencent Hunyuan3D-1.0 (GitHub) is a unified framework for 3D content generation that supports both text and image inputs. The system uses a novel two-stage pipeline:
- Multi-view Generation: A diffusion model rapidly produces multi-view RGB images (4 seconds)
- 3D Reconstruction: A neural network converts these views into textured 3D meshes (7 seconds)
Key advantages include:
- Dual support for text/image prompts through integration with Hunyuan-DiT
- Significant speed improvements (10-25s generation time)
- Quality preservation through noise-handling reconstruction
- Open-source implementation with pre-trained models
- Commercial-friendly license (except baking module)
The framework offers lite and standard versions, with the standard model achieving superior quality while maintaining practical generation speeds. Installation requires CUDA-enabled GPUs and dependencies like PyTorch3D, with pre-trained models available via Hugging Face Hub.
Advanced Multi-Stage Models
5. Unique3D (AiuniAI/Unique3D)
Four-Stage Pipeline:
- Single image → 4 views (256x256)
- Upscale to 512x512 → 2048x2048
- Generate normal maps
- Create textured 3D mesh
Required Models:
- sdv1.5-pruned-emaonly
- controlnet-tile
- ip-adapter_sd15
- OpenCLIP-ViT-H-14
- RealESRGAN_x4plus
Unique3D (Project Page) is an open-source framework for rapid 3D mesh generation from single images, featuring:
Core Capabilities
- 🚀 30-second generation of textured 3D meshes
- 🖼️ Handles both object-centric and scene-level images
- 🔄 Two-stage pipeline: Multi-view synthesis → Mesh reconstruction
Technical Highlights
- Hybrid architecture combining diffusion models with geometric processing
- Adaptive view selection mechanism
- Normal-map guided mesh refinement
Implementation Features
- Multiple deployment options:
- Local Gradio interface (Demo)
- ComfyUI integration
- Docker support
- Windows/Linux compatibility
- MIT-licensed commercial use
The system achieves 1280×1280 resolution outputs while maintaining 10× speed advantage over previous methods, though performance depends on input image quality and object orientation. Current limitations include sensitivity to occlusions and requirement for clear object boundaries in input images.
6. Era3D MVDiffusion
- VRAM: Minimum 16GB required
- Output: 6 multi-view images + normal maps (512x512)
- Source: pengHTYX/Era3D
Era3D (Project Page) introduces a high-resolution 3D generation framework with these key features:
Core Innovation
- 🖼️ 512×512 multiview synthesis using row-wise attention
- 🔄 Two-phase generation:
- Multi-view RGB/Normal maps (4s)
- Instant-NSR mesh reconstruction (7s)
Technical Highlights
- Orthogonal projection variant for input-view consistency
- Hybrid training strategy combining 2D/3D supervision
- Memory-efficient architecture (8GB VRAM usage)
Implementation
- Requirements:
- CUDA 11.8 + RTX 3090/4090 GPUs
- Specialized dependencies (xformers, nvdiffrast)
- Deployment options:
- Local inference scripts
- Pre-trained models via Hugging Face
- Background removal integration
The system achieves 3D reconstruction in ~11 seconds total while handling complex textures, though requires careful background preprocessing. Current limitations include AGPL-3.0 license constraints and sensitivity to input image perspective distortions.
7. InstantMesh Reconstruction
- Input: Multi-view images (white background)
- Output: RGB textured 3D mesh
- Compatibility: Works with Zero123++ and CRM MVDiffusion
InstantMesh (Paper) is an efficient framework for single-image 3D generation with these key features:
Core Architecture
- 🕒 30-second generation pipeline:
- Multi-view synthesis (4s)
- Sparse-view reconstruction (26s)
- 🔄 Dual representation:
- Neural Radiance Fields (NeRF)
- Explicit textured meshes
Technical Highlights
- Hybrid mesh baking combining vertex colors & texture maps
- Memory-optimized attention mechanisms (8GB VRAM usage)
- Background-aware reconstruction via rembg integration
Implementation
- Multiple deployment options:
- Local Gradio/CLI
- Docker containers
- ComfyUI plugin
- Training support for:
- Custom reconstruction models
- Zero123++ fine-tuning
- Apache 2.0 licensed commercial use
The system achieves 512×512 resolution outputs while maintaining 10× speed advantage over optimization-based methods, though requires high-quality input images for best results. Current limitations include dependency on CUDA 12.1+ and sensitivity to input image perspective.
Specialized Models
8. CharacterGen (zjp-shadow/CharacterGen)
- Purpose: Character modeling from front view
- Feature: Works with Unique3D for enhanced results
CharacterGen (Paper) introduces an anime-style 3D character generation system with these key features:
Core Architecture
- 🎭 Two-phase generation:
- Pose-canonicalized multi-view synthesis
- Geometry-consistent 3D reconstruction
- 🔄 VRM format support for animation-ready outputs
Technical Highlights
- Multi-view pose normalization for consistency
- Hybrid rendering pipelines:
- Blender VRM add-on
- Three.js implementation
- Anime3D dataset compatibility
Implementation
- Deployment options:
- Integrated Gradio web interface
- Modular 2D/3D stage separation
- Requirements:
- CUDA-enabled GPUs
- PyTorch3D dependencies
- Apache 2.0 licensed commercial use
The system achieves 512×512 resolution character generation while maintaining anatomical consistency through pose calibration. Current limitations include dependency on VRM model preprocessing and requirement for high-quality input images. Pre-trained weights are available via Hugging Face.
9. Zero123++ (SUDO-AI-3D/zero123plus)
- Output: 6 view images (320x320)
- Views: Front, Back, Left, Right, Top, Down
Zero123++ (Paper) is a multi-view diffusion model for 3D generation with these key features:
Core Architecture
- 🖼️ Single-image to 6-view synthesis (5GB VRAM)
- 📐 Fixed camera parameters:
- Azimuth: 30° increments
- Elevation: 20°/-10° (v1.2)
- FOV: 30° fixed output
Technical Highlights
- Depth ControlNet for geometric consistency
- Normal map generation for alpha matting
- Adaptive step scheduling (28-100 steps)
Implementation
- Deployment options:
- Diffusers custom pipeline
- Streamlit/Gradio interfaces
- Hugging Face integration
- Requirements:
- CUDA-enabled GPUs
- Torch 2.0+ recommended
The model achieves 512×512 resolution outputs with CC-BY-NC licensed weights, requiring square input images (≥320px). Current limitations include non-commercial license restrictions and fixed viewpoint outputs. Pre-trained models available via Hugging Face.
10. TripoSR
- Function: NeRF to 3D mesh conversion
- Method: Marching cubes algorithm
- Source: VAST-AI-Research/TripoSR
TripoSR (Paper) is a state-of-the-art open-source model for rapid 3D reconstruction from single images, featuring:
Core Architecture
- ⚡️ 0.5-second generation on A100 GPUs
- 🔄 Two-phase processing:
- Multi-view synthesis
- Feed-forward 3D reconstruction
Technical Highlights
- MIT-licensed commercial use
- 6GB VRAM requirement per image
- Texture baking support (up to 2048px)
Implementation
- Requirements:
- CUDA version matching PyTorch's CUDA version
- Python 3.8+
- Deployment options:
- Command-line interface
- Local Gradio web demo
- Batch processing support
The model achieves real-time performance while maintaining quality through its LRM-based architecture. Current limitations include dependency on CUDA version alignment and requirement for square input images. Pre-trained weights are included in the repository under MIT license.
11. Wonder3D
- Output: 6 consistent views + normal maps
- Source: xxlong0/Wonder3D
Wonder3D++ (Project Page) introduces a cross-domain diffusion framework for 3D generation with these key features:
Core Architecture
- 🕒 3-minute generation pipeline:
- Multi-view RGB/Normal synthesis (2m)
- Cascaded mesh reconstruction (1m)
- 🔄 Cross-domain attention mechanism
Technical Highlights
- AGPL-3.0 licensed code (commercial restrictions)
- Iterative refinement through
num_refineparameter - Camera projection support:
- Orthographic (
--camera_type ortho) - Perspective (
--camera_type persp)
- Orthographic (
Implementation
- Training requirements:
- 8x A100 GPUs (stage 1-3)
- Custom dataset preparation
- Inference options:
- Local CLI/Gradio
- Hugging Face integration
- Colab demo via @camenduru
The system achieves 512×512 resolution outputs while maintaining geometric consistency through multi-view attention. Current limitations include AGPL license constraints and dependency on accurate foreground masks. Pre-trained models require commercial licensing agreements.
12. Large Multiview Gaussian (3DTopia/LGM)
- Speed: Under 30 seconds on RTX3080
- Feature: Gaussian to mesh conversion
- Source: ashawkey/LGM
LGM (Large Multi-View Gaussian Model) (Project Page) introduces a 3D generation framework using Gaussian Splatting, featuring:
Core Architecture
- 🌟 Dual-mode generation:
- Text-to-3D via MVDream/ImageDream
- Image-to-3D through multi-view synthesis
- ⚡️ Real-time Gaussian Splatting reconstruction
Technical Highlights
- Modified depth-aware rasterization pipeline
- Hybrid training strategy:
- 80K Objaverse subset pre-training
- Multi-GPU distributed training
- MIT-licensed commercial use
Implementation
- Requirements:
- CUDA 11.8 + xformers
- RTX 3090/4090 GPUs recommended
- Deployment options:
- Local Gradio interface
- Replicate API integration
- Mesh conversion to *.ply format
The system achieves 512×512 resolution outputs while maintaining 10GB VRAM usage through optimized Gaussian parameterization. Current limitations include dependency on specific CUDA versions and requirement for square input images. Pre-trained weights available via Hugging Face.
13. Triplane Gaussian Transformers
- Speed: Under 10 seconds on RTX3080
- Feature: Quick Gaussian generation
- Source: VAST-AI-Research/TriplaneGaussian
TriplaneGaussian (Paper) introduces a hybrid 3D reconstruction framework with these key features:
Core Architecture
- ⚡️ Sub-second reconstruction (A100 GPU)
- 🔄 Dual representation:
- Triplane features (implicit)
- 3D Gaussian Splatting (explicit)
Technical Highlights
- Transformer-based geometry prediction
- Adaptive camera distance parameter (1.9-2.1)
- SAM integration for background removal
- Apache 2.0 licensed commercial use
Implementation
- Requirements:
- CUDA-enabled GPUs
- PyTorch3D + diff-gaussian-rasterization
- Deployment options:
- Colab Notebook
- Local Gradio with custom renderer
- Hugging Face model integration
The system achieves real-time performance through optimized Gaussian parameterization, though requires careful camera distance tuning for optimal results. Current limitations include dependency on foreground segmentation and training dataset scale constraints.
But wait - there's more! You can also:
- Make 3D models look smooth and professional
- Create spinning videos of your 3D models
- Save your work in different 3D file formats
- Fix up models that aren't quite right
Getting Started Is Dead Easy
Want to try it yourself? Here's how:
-
The simplest way is through ComfyUI-Manager. It's like installing an app on your phone - just click and you're done!
-
If you're more of a DIY person, you can download it yourself from GitHub. Just copy a few commands, and you're ready to go.
-
Got a Windows PC? There's even a special version called Comfy3D-WinPortable that's super easy to set up.
What's Coming Next?
The folks making this tool have big plans:
- They're working on making it even better at turning 3D point clouds into proper models
- New ways to estimate camera positions from photos
- More cool features for working with multiple views of objects
Tips from Someone Who's Used It
Here are some things I learned while playing with it:
-
If you get any OpenGL errors (those annoying technical messages), just tick the 'force_cuda_rasterize' box. Works like a charm!
-
Having trouble with the coordinates? Remember it uses a system where:
- Up is +y
- Right is +x
- Forward is +z
It's like a video game coordinate system - once you get it, it makes total sense!
Wrapping Up
This tool is honestly amazing for anyone interested in 3D creation. Whether you're making game assets, doing 3D printing, or just playing around with 3D art, it makes everything so much easier.
The best part? It's always getting better. The team behind it is constantly adding new features and making improvements. And because it's open source, you can even help make it better if you're into coding!
Give it a try - you might be surprised at how easy it is to start creating cool 3D stuff!
Related Posts
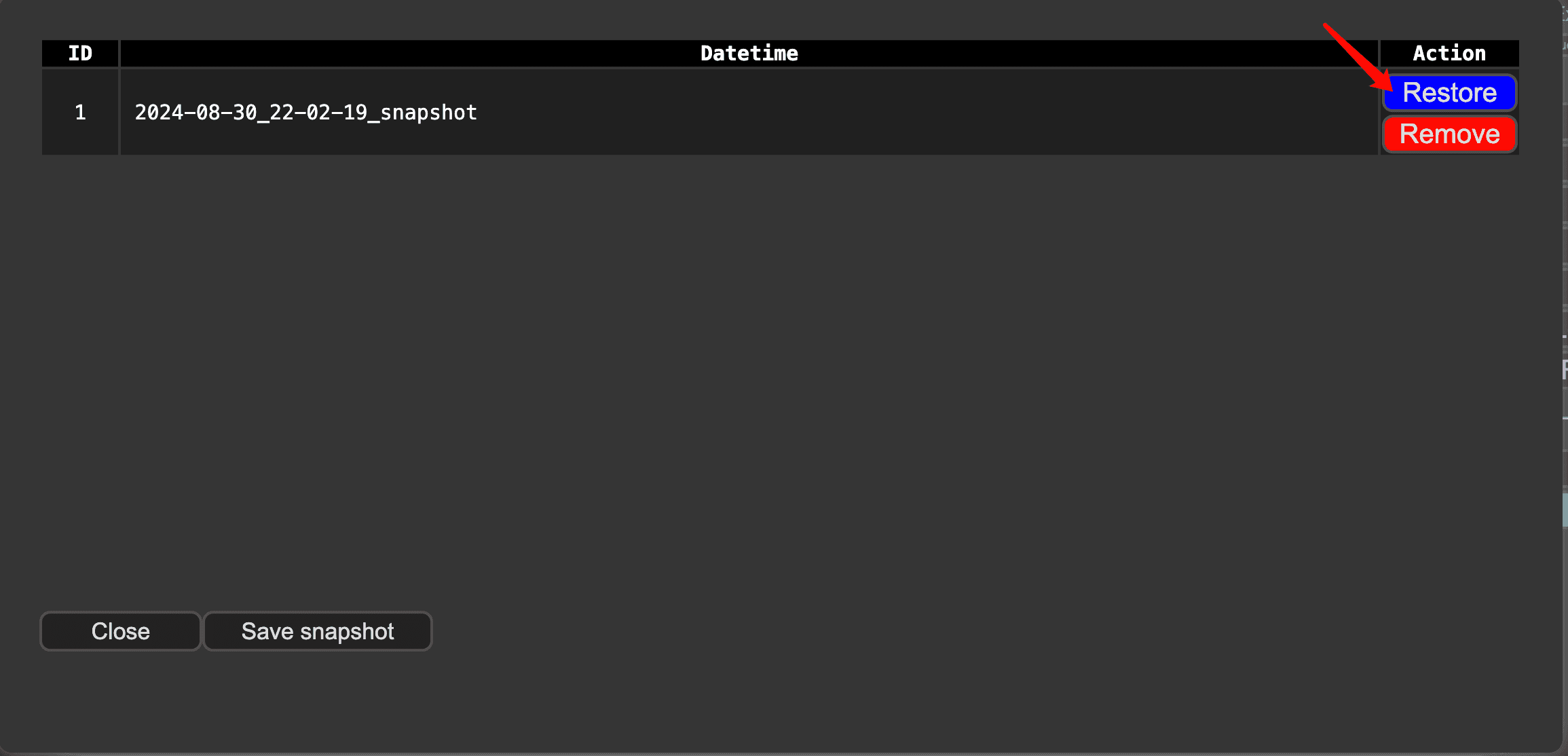
ComfyUI Snapshot Manager: Managing Custom Nodes and Environments
Struggling to keep your ComfyUI custom nodes and enviroments organized? ComfyUI Snapshot Manager's got your back.
ComfyUI Keyboard Shortcuts: Turbocharge Your Workflow Now!
Tired of sluggish workflows? These game-changing ComfyUI keyboard shortcuts will skyrocket your productivity.
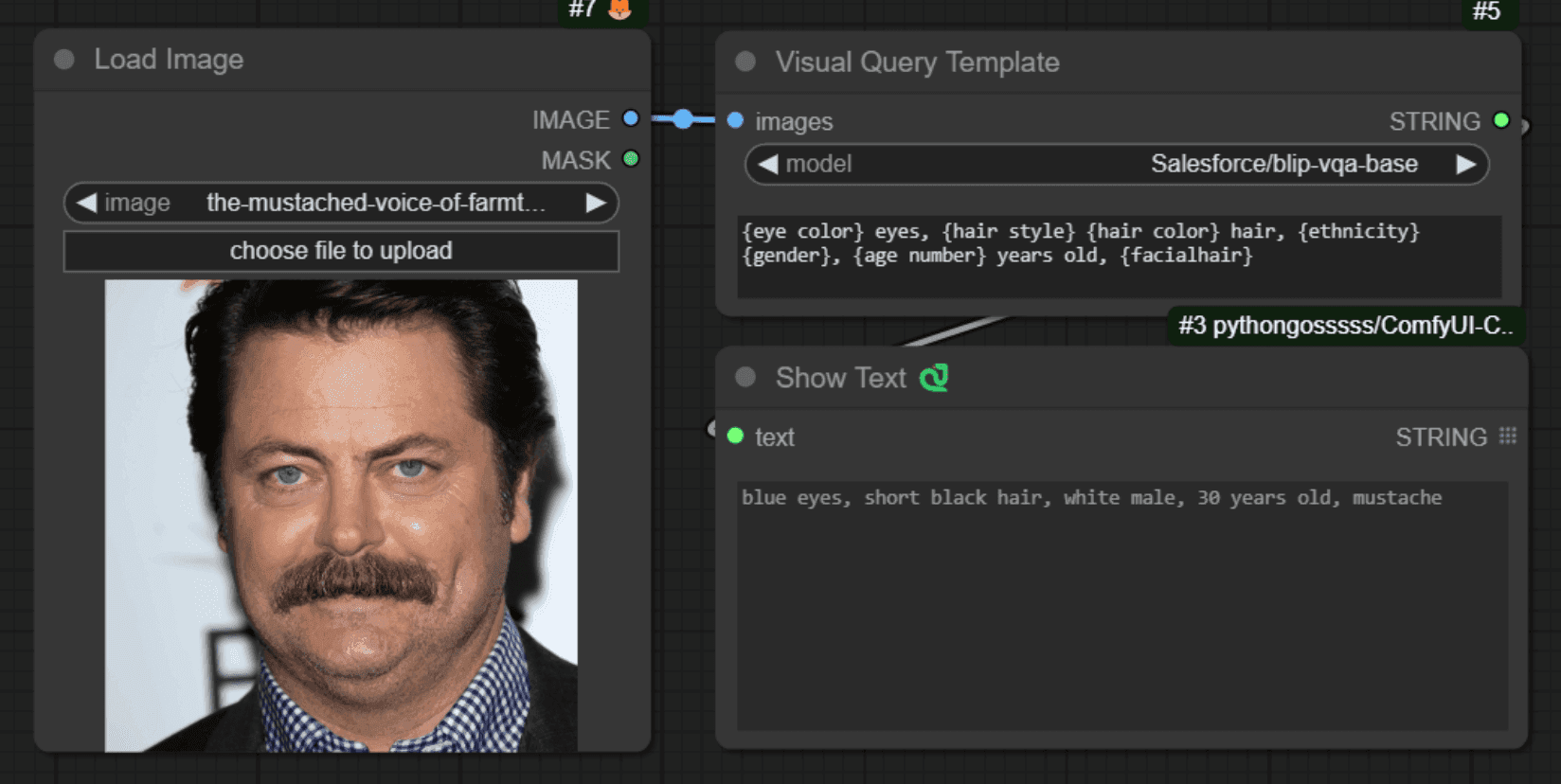
Comfyui VisualQueryTemplate Node for Precision Control
This node, named "VisualQueryTemplateNode", is designed to perform Visual Question Answering (VQA) tasks on images.

ComfyUI-CogVideoXWrapper: Turn Text into Video with AI
ComfyUI-CogVideoXWrapper is a tool that allows you to use CogVideoX models within ComfyUI. ComfyUI-CogVideoXWrapper supports the following CogVideoX models: CogVideoX-5b, CogVideoX-Fun, CogVideoX-5b-I2V